《人工智能》课程
实验报告
网络与信息安全学院
班 级: 20180XX
姓 名: XXX
学 号: 20009XXXX
提交时间: 2023. 4. 20
基于神经网络的MNIST手写数字识别
一、实验目的
掌握运用神经网络模型解决有监督学习问题
掌握机器学习中常用的模型训练测试方法
了解不同训练方法的选择对测试结果的影响
二、实验内容
MNIST数据集
本实验采用的数据集MNIST是一个手写数字图片数据集,共包含图像和对应的标签。数据集中所有图片都是28x28像素大小,且所有的图像都经过了适当的处理使得数字位于图片的中心位置。MNIST数据集使用二进制方式存储。图片数据中每个图片为一个长度为784(28x28x1,即长宽28像素的单通道灰度图)的一维向量,而标签数据中每个标签均为长度为10的一维向量。
分层采样方法
分层采样(或分层抽样,也叫类型抽样)方法,是将总体样本分成多个类别,再分别在每个类别中进行采样的方法。通过划分类别,采样出的样本的类型分布和总体样本相似,并且更具有代表性。在本实验中,MNIST数据集为手写数字集,有0~9共10种数字,进行分层采样时先将数据集按数字分为10类,再按同样的方式分别进行采样。
神经网络模型评估方法
通常,我们可以通过实验测试来对神经网络模型的误差进行评估。为此,需要使用一个测试集来测试模型对新样本的判别能力,然后以此测试集上的测试误差作为误差的近似值。两种常见的划分训练集和测试集的方法:
留出法(hold-out)直接将数据集按比例划分为两个互斥的集合。划分时为尽可能保持数据分布的一致性,可以采用分层采样(stratified sampling)的方式,使得训练集和测试集中的类别比例尽可能相似。需要注意的是,测试集在整个数据集上的分布如果不够均匀还可能引入额外的偏差,所以单次使用留出法得到的估计结果往往不够稳定可靠。在使用留出法时,一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
k折交叉验证法(k-fold cross validation)先将数据集划分为k个大小相似的互斥子集,每个子集都尽可能保持数据分布的一致性,即也采用分层采样(stratified sampling)的方法。然后,每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集,这样就可以获得k组训练集和测试集,从而可以进行k次训练和测试。最终返回的是这k个测试结果的均值。显然,k折交叉验证法的评估结果的稳定性和保真性在很大程度上取决于k的取值。k最常用的取值是10,此外常用的取值还有5、20等。
三、实验方法设计
实验环境
1.VSCODE
2.anaconda==4.14.0
3.python==3.7
4.TensorFlow–gpu==1.15.0
5.Keras==2.3.1
6.实验报告编辑器:typora
介绍实验中程序的总体设计方案、关键步骤的编程方法及思路,主要包括:
因为之前用过pytorch进行机器学习的训练和学习,所以本作业使用pytorch进行建模和训练。
标准训练流程如下:导入包->设定初始值->加载数据集(预处理)->建立模型->训练->测试->评估
其中需要对加载数据集进行处理,把留出法的比例进行调整来观察结果。
其次要使用k折交叉验证法进行对比测试。
为了表明k折交叉验证法与留出法的效果对比,我建立了连个模型,一个是按照标准流程建立的优秀的模型。一个是用作对比k折交叉验证法与留出法效果对比的劣质模型。
含有tensorflow部分代码,在四、4中。
- 设置初始值
2
3
4
5
6
>std = [0.5]
># batch size
>BATCH_SIZE =128
>Iterations = 1 # epoch
>learning_rate = 0.01
- 优化器与损失函数
2
>optimizer = torch.optim.SGD(model.parameters(),learning_rate)
- 训练代码
2
3
4
5
6
7
8
9
10
11
12
13
model.train() # setting up for training
for batch_idx, (data, target) in enumerate(train_loader): # data contains the image and target contains the label = 0/1/2/3/4/5/6/7/8/9
data = data.view(-1, 28*28).requires_grad_()
optimizer.zero_grad() # setting gradient to zero
output = model(data) # forward
loss = criterion(output, target) # loss computation
loss.backward() # back propagation here pytorch will take care of it
optimizer.step() # updating the weight values
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
- 测试代码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for batch_idx, (data, target) in enumerate(val_loader):
data = data.view(-1, 28*28).requires_grad_()
output = model(data)
test_loss += criterion(output, target).item() # sum up batch loss
pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item() # if pred == target then correct +=1
test_loss /= len(val_loader.dataset) # average test loss
if train == False:
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.4f}%)\n'.format(
test_loss, correct, val_loader.sampler.__len__(),
100. * correct / val_loader.sampler.__len__() ))
if train == True:
print('\nTrain set: Average loss: {:.4f}, Accuracy: {}/{} ({:.4f}%)\n'.format(
test_loss, correct, val_loader.sampler.__len__(),
100. * correct / val_loader.sampler.__len__() ))
return 100. * correct / val_loader.sampler.__len__()
1)模型构建的程序设计(伪代码或源代码截图)及说明解释 (10分)
训练模型
1 | class Net(nn.Module): |
我用了一层conv和一层pool来获取cherng图片的特征。之后把这些特征减小为10个层,所以用flatten把特征集中成vector后,再用一个全连接层连接到输出层。
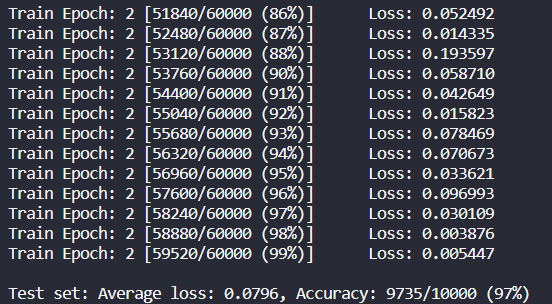
使用留出法原始的训练比例,两个Epoch,得到的结果很好。达到97%。
为了对比留出法及K折验证法建立的简陋模型
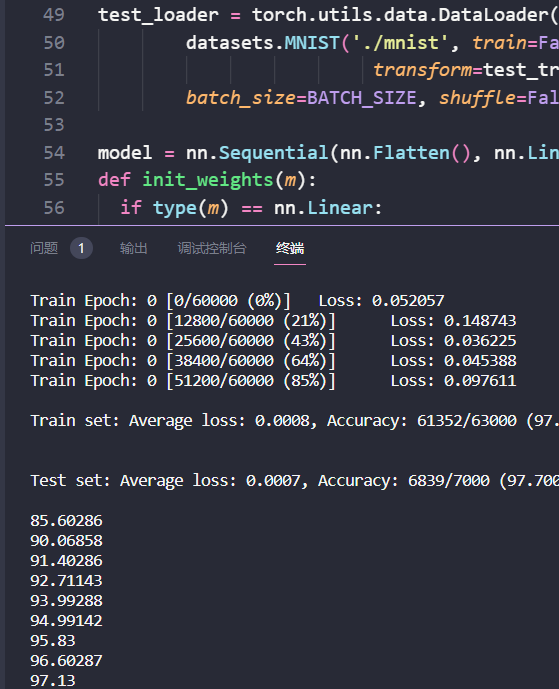
1 | model = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(),nn.Linear(256, 10)) |
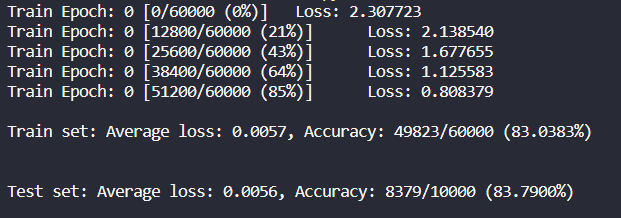
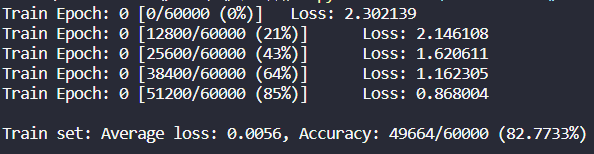
可以看到这个简陋模型得到的结果很差,准确率只有83%,用于之后的K折校验法的对比组。预处理和上述相同,Epoch只有一组。
2)模型迭代训练的程序设计(伪代码或源代码截图)及说明解释 (10分)
1 | def train(model, optimizer,criterion,epoch): |
先注意到因為 training 和 testing 時 model 會有不同行為,所以用 model.train() 把 model 調成 training 模式。
接著 iterate 過 batch_idx,每個 batch_idx會 train 過整個 training set。每個 dataset 會做 batch training。
接下來就是重點了。基本的步驟:zero_grad、model(data)、取 loss、back propagation 算 gradient、最後 update parameter。前面都介紹過了,還不熟的可以往前翻。
3)模型训练过程中周期性测试的程序设计(伪代码或源代码截图)及说明解释(周期性测试指的是每训练n个step就对模型进行一次测试,得到准确率和loss值)(10分)
我选用了每100步进行一个打印的频率,打印训练进度和Loss值,最后打印平均损失值和准确率。
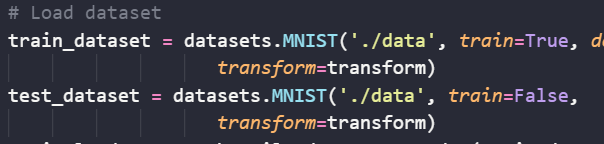
4)分层采样的程序设计(伪代码或源代码截图)及说明解释 (10分)
1 | train_transform = transforms.Compose([ |
2
3
4
5
6
7
8
9
test_acc = torch.zeros([Iterations])
train_acc = torch.zeros([Iterations])
## training the logistic model
for i in range(Iterations):
train(model, optimizer,criterion,i)
train_acc[i] = test(model, criterion, train_loader, i,train=True) #Testing the the current CNN
test_acc[i] = test(model, criterion, test_loader, i)
torch.save(model,'perceptron.pt')使用了系统自带的minist数据分类器。
5)k折交叉验证法的程序设计(伪代码或源代码截图)及说明解释 (10分)
- mnist数据集的训练集和测试集的合并
1 |
|
- 使用Sklearn中的KFold进行数据集划分,并且转换回pytorch类型的Dataloader
1 | kf = KFold(n_splits=k_split_value,shuffle=True, random_state=0) # init KFold |
- 完整的代码
1 |
|
- 按循序打印结果
1 | testAcc_compare_map = {} |
testAcc_compare_map是将不同k值下训练的结果保存起来,之后我们可以通过这个字典变量,计算出rmse ,比较不同k值下,实验结果的鲁棒性。
四、实验结果展示
展示程序界面设计、运行结果及相关分析等,主要包括:
1)模型在验证集下的准确率(输出结果并截图)(10分)
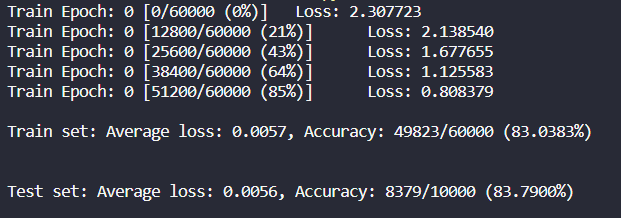
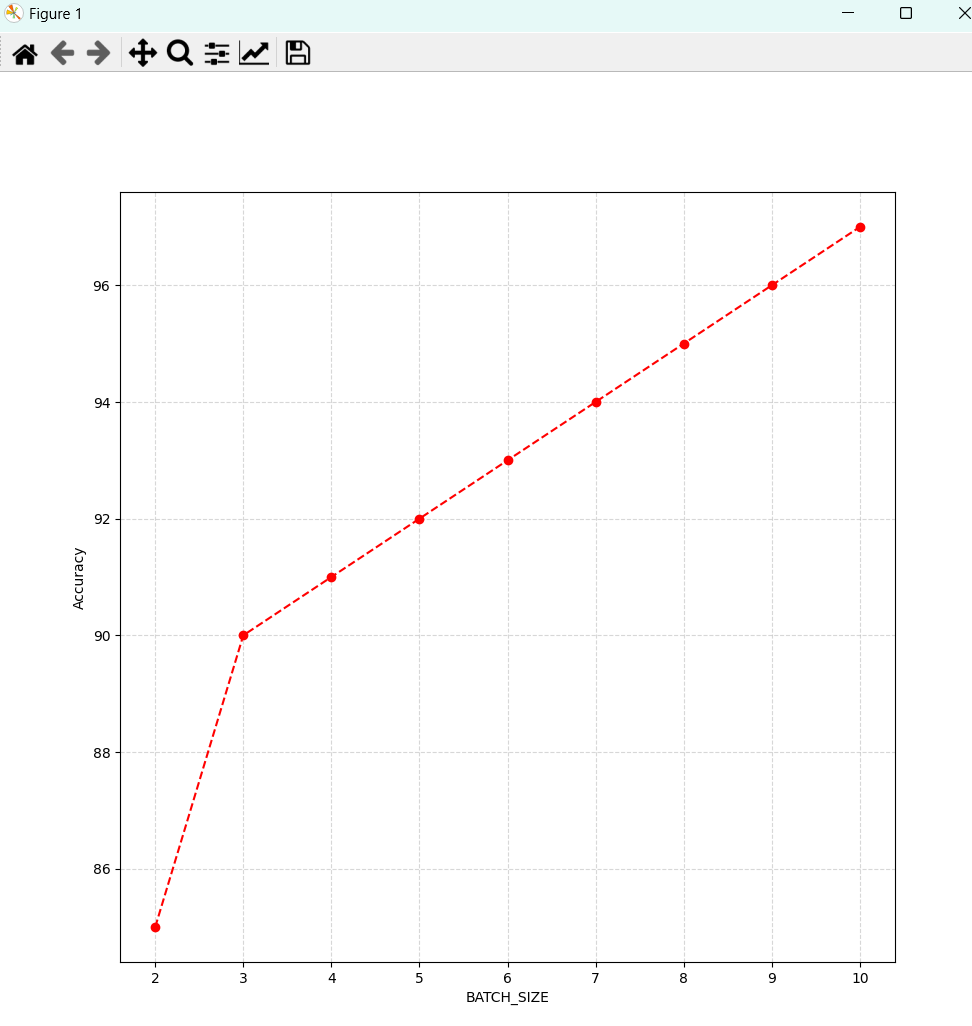
下面的实验是k值为[2,10]下的结果,训练模型为简陋模型。
对照组:简陋模型,epoch为1,分层抽样(正确率只有83.79%)
k折校验:简陋模型,epoch为1,K折交叉验证(K值为2到10)准确率越来越大
2)不同模型参数(隐藏层数、隐藏层节点数)对准确率的影响和分析 (10分)
本次实验中只探讨了简陋版模型与卷积模型的对比:
其中简陋版模型如下,先把图片变为一个以为张量,然后由一个全连接层链接,接入到ReLu层中,然后接入全连接层,可以看到,并没有使用卷积层,在epoch=1的情况下只有83%的准确率。
卷积模型如下,先定义卷积卷积层,输入通道为1,输出为32,核大小为3,一个Dropout2d层,以0.25的概率将通道输入置零,防止过拟合。然后是一个全连接层,输入为5408,输出为10,映射到10个分类结果。在forward中首先通过卷积层进行卷积,然后通过ReLU进行非线性变换,然后使用最大池化层进行采样,将图签尺寸缩小一半,然后用Dropout2d防止过拟合,接着把输出的张良展平为一维,并传入全连接层。
在
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def __init__(self):
super(Net, self).__init__()
self.conv = nn.Conv2d(1, 32, 3)
self.dropout = nn.Dropout2d(0.25)
self.fc = nn.Linear(5408, 10)
def forward(self, x):
x = self.conv(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout(x)
x = torch.flatten(x, 1)
x = self.fc(x)
output = F.log_softmax(x, dim=1)
return output可以看到在epoch=1的情况下准确率达到97%,拟合效果非常好
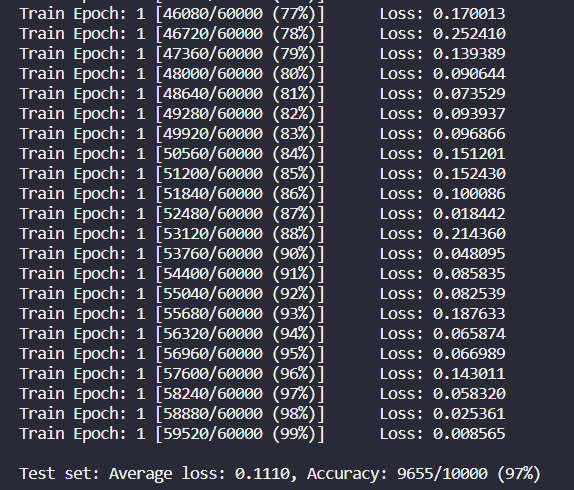
3)不同训练参数(batch size、epoch num、学习率)对准确率的影响和分析 (10分)
- 注:默认值:在讨论某一变化时,其他值不变
2
3
>Iterations = 1 # epoch
>learning_rate = 0.01原始结果(83%)
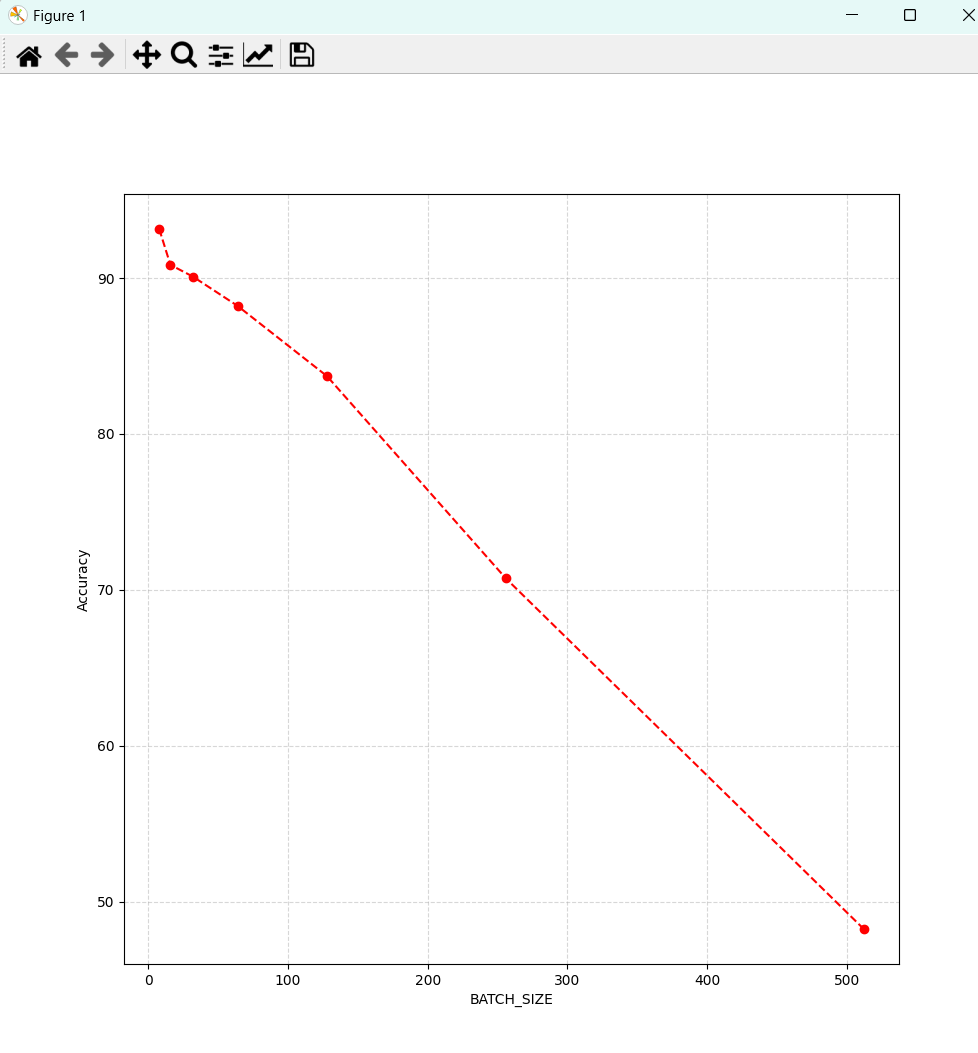
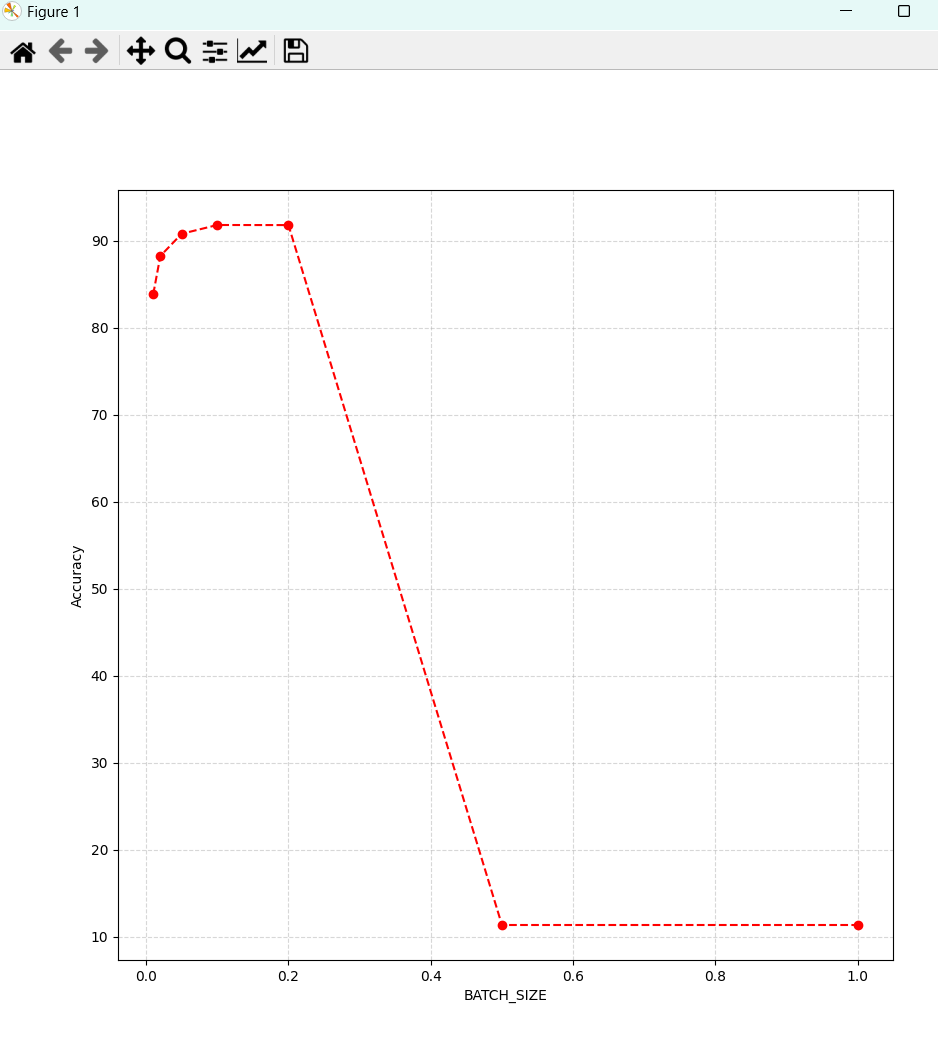
- BATCH_SIZE讨论(可以发现当BATCH_SIZE越大时,准确率直线下降)
- epoch讨论(可以发现随着epoch的增大,准确率有较大提升,但是随着epoch越来越大,准确率增长越来越慢)
2
[83.83,88.370,90.290,91.260,92.420,93.36]
学习率
可以看到,当学习率增大时,准确率有所增加,但是当学习率大于0.2时,准确率急速下滑到11%左右,也就是说,10个手写体正确率只有1个,趋于随机分布,是一个非常不好的模型,可见,学习率的选择至关重要。
2
>[83.83,88.230,90.78,91.79,91.78,11.35,11.35]

4)留出法不同比例对结果的影响和分析 (10分)
因为pytorch中的训练集是固定输出的,对其更改较难,所以本小节使用TensorFlow进行实验:
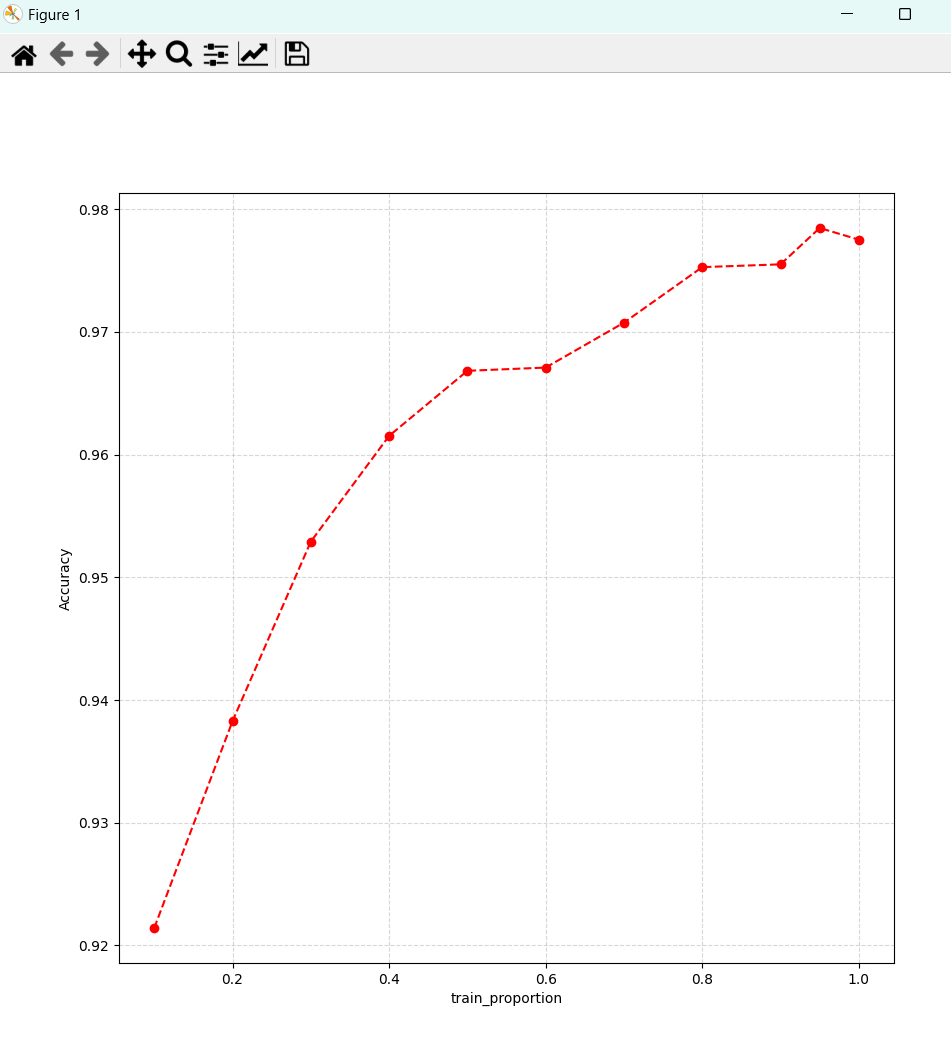
数据集划分:其中a为训练比率,总共有70000个样本,按照比例进行训练和测试,结果如下
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
>a = 0.8
>from keras.datasets import mnist
>(x_train_image,y_train_label),(x_test_image,y_test_label)=mnist.load_data()
># x_all = x_train_image + x_test_image
>temp = np.append( x_train_image , x_test_image)
>x_all = temp.reshape(70000,28,28)
>print(len(y_train_label))
>y_lable = np.append(y_train_label,y_test_label)
>train_num = int(60000*a)
>x_train_image = x_all[:train_num]
>y_train_label = y_lable[:train_num]
>x_test_image = x_all[train_num:]
>y_test_label = y_lable[train_num:]
>x_Train=x_train_image.reshape(train_num,784).astype('float32')
>x_Test=x_test_image.reshape(70000-train_num,784).astype('float32')
2
>[0.9213, 0.9381, 0.9528, 0.9620, 0.9666, 0.9673, 0.9709, 0.9752, 0.9758, 0.9784, 0.9780]可以看到随着训练样本的比率上升,总体的准确率也对应的明显的上升了,但是最后一组0.9999比率的组,较前一组0.95有所下降,这表明过大的训练比率对结果也会产生损害。
5)k折交叉验证法不同k值对结果的影响和分析 (10分)
把k值从2-10进行迭代计算,其他参数不变,结果为:
2
3
4
5
6
7
8
>for k_split_value in range(2, 10+1):
print('now k_split_value is:', k_split_value)
testAcc_compare_map[k_split_value] = cross_validation(k_split_value)
>for key in testAcc_compare_map:
print(np.mean(testAcc_compare_map[key]))
可见K值对结果影响很大,且在一定范围内,越大越好。
五、实验总结及心得
本次实验熟知了pytorch和TensorFlow的使用,还有机器学习的整体流程和处理概况,解决了出现的诸多问题,尤其是在配置TensorFlow版本时出现的问题,熟知了基本的图像处理模型,以及卷积模型的基本构建。
在参数调配方面,详细了解了分层取样法,k折交叉验证法的使用以及效果还有比例的调试。还有在关键参数如batch size、epoch num、学习率方面有着较好的经验总结。