defforward(self, x): x = self.conv(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout(x) x = torch.flatten(x, 1) x = self.fc(x) output = F.log_softmax(x, dim=1) return output
# Define image transform transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) # mean and std for the MNIST training set ])
# MNIST Test dataset and dataloader declaration transform = transforms.Compose([ transforms.ToTensor(), ]) train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform) test_loader = torch.utils.data.DataLoader(train_dataset,batch_size=1, shuffle=True) # Define what device we are using print("CUDA Available: ",torch.cuda.is_available()) device = torch.device("cuda"if (use_cuda and torch.cuda.is_available()) else"cpu")
# Initialize the network model = Net().to(device)
# Load the pretrained model model.load_state_dict(torch.load("mnist_cnn.pt", map_location='cpu'))
# Set the model in evaluation mode. In this case this is for the Dropout layers model.eval()
b)攻击函数创建
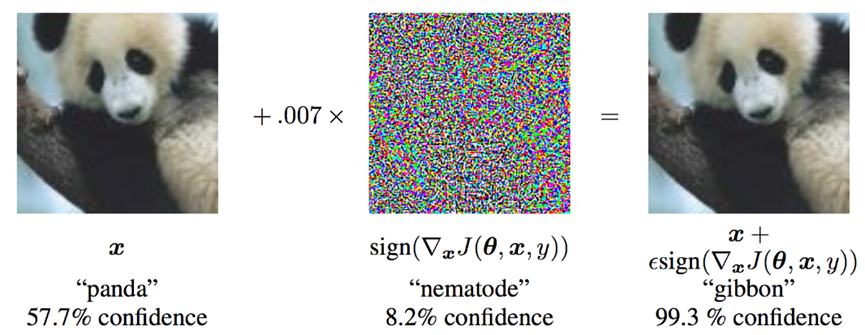
现在,我们可以通过扰动原始输入来定义创建对抗性示例的函数。Fgsm 攻击函数有三个输入,图像是原始清晰图像(xx) ,ε 是像素级扰动量(εε) ,data _ grad 是损失的梯度,输入图像(∇xJ(θ,x,y))。然后,该函数创建扰动图像 $$ perturbed_image=image+epsilon∗sign(data_grad)=x+ϵ∗sign(∇ x J(θ,x,y)) $$
1 2 3 4 5 6 7 8 9 10
# FGSM attack code deffgsm_attack(image, epsilon, data_grad): # Collect the element-wise sign of the data gradient sign_data_grad = data_grad.sign() # Create the perturbed image by adjusting each pixel of the input image perturbed_image = image + epsilon*sign_data_grad # Adding clipping to maintain [0,1] range perturbed_image = torch.clamp(perturbed_image, 0, 1) # Return the perturbed image return perturbed_image
c)开始攻击
1 2 3 4 5 6 7 8
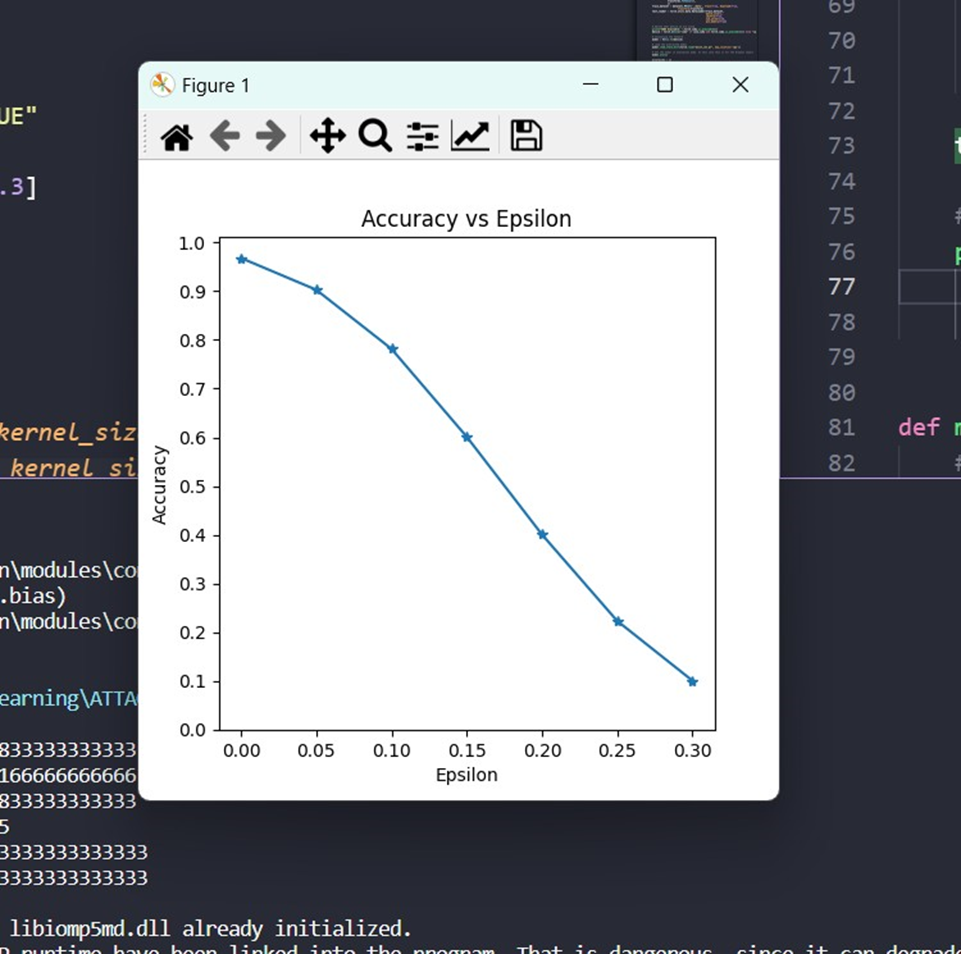
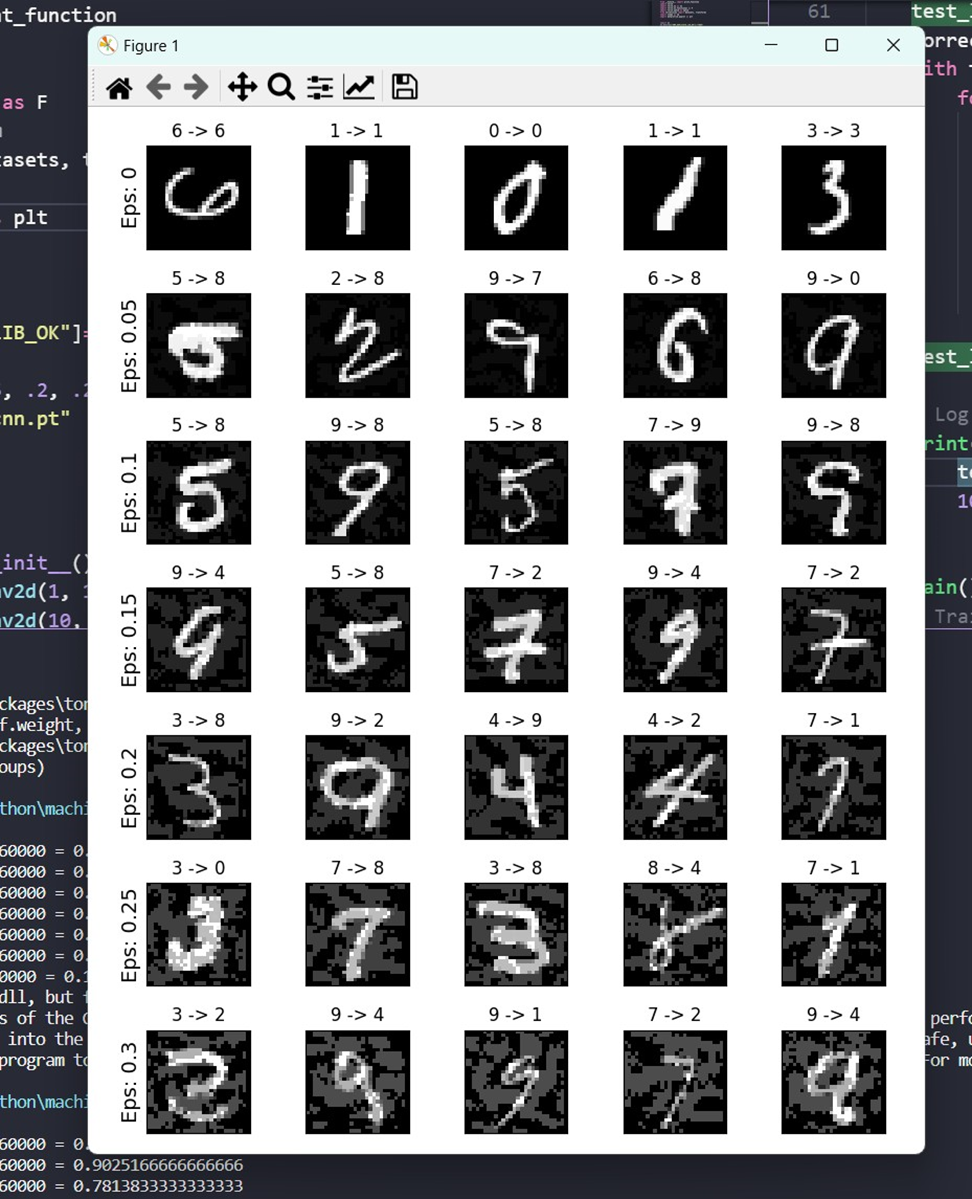
accuracies = [] examples = []
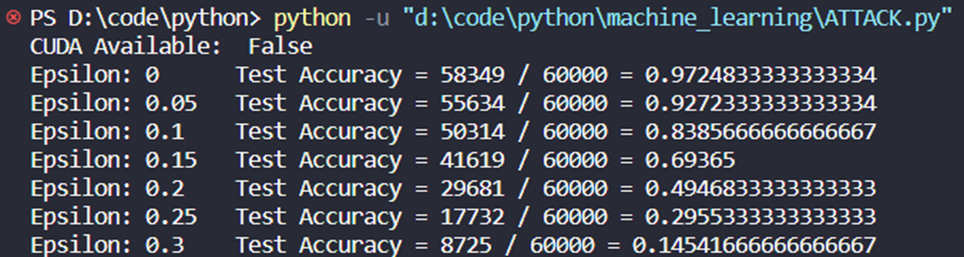
# Run test for each epsilon for eps in epsilons: acc, ex = test(model, device, test_loader, eps) accuracies.append(acc) examples.append(ex)