教程来自:https://zhuanlan.zhihu.com/p/137571225
在本文中,我们将在PyTorch中构建一个简单的卷积神经网络,并使用MNIST数据集训练它识别手写数字。在MNIST数据集上训练分类器可以看作是图像识别的“hello world”。
MNIST包含70,000张手写数字图像: 60,000张用于培训,10,000张用于测试。图像是灰度的,28x28像素的,并且居中的,以减少预处理和加快运行。
1 设置环境
在本文中,我们将使用PyTorch训练一个卷积神经网络来识别MNIST的手写数字。PyTorch是一个非常流行的深度学习框架,比如Tensorflow、CNTK和caffe2。但是与其他框架不同的是,PyTorch具有动态执行图,这意味着计算图是动态创建的。
先去官网上根据指南在PC上装好PyTorch环境,然后引入库。
1 | import torch |
2 准备数据集
导入就绪后,我们可以继续准备将要使用的数据。但在那之前,我们将定义超参数,我们将使用的实验。在这里,epoch的数量定义了我们将循环整个训练数据集的次数,而learning_rate和momentum是我们稍后将使用的优化器的超参数。
1 | n_epochs = 3 |
对于可重复的实验,我们必须为任何使用随机数产生的东西设置随机种子——如numpy和random!
现在我们还需要数据集的dataloader。这就是TorchVision发挥作用的地方。它让我们用一种方便的方式来加载MNIST数据集。我们将使用batch_size=64进行训练,并使用size=1000对这个数据集进行测试。下面的Normalize()转换使用的值0.1307和0.3081是MNIST数据集的全局平均值和标准偏差,这里我们将它们作为给定值。
TorchVision提供了许多方便的转换,比如裁剪或标准化。
1 | train_loader = torch.utils.data.DataLoader( |
我这里下载文件路径显示Forbiden 403,打开网页也发现是403,看先好多issue都是这个样子,找到了解决方法:先到这个地址把我们要的四个文件下载好
https://blog.csdn.net/qq_38501425/article/details/132140406
然后们摁住Ctrl进去到MNIST源代码里找到resources改为你下载好的本地路径就好了,比如
1 | resources = [ |
然后程序就可以正常读取了
除了数据集和批处理大小之外,PyTorch的DataLoader还包含一些有趣的选项。例如,我们可以使用num_workers > 1来使用子进程异步加载数据,或者使用固定RAM(通过pin_memory)来加速RAM到GPU的传输。但是因为这些在我们使用GPU时很重要,我们可以在这里省略它们。
现在让我们看一些例子。我们将为此使用test_loader。
让我们看看一批测试数据由什么组成。
1 | examples= enumerate(test_loader) |
example_targets是图片实际对应的数字标签:

一批测试数据是一个形状张量:

这意味着我们有1000个例子的28x28像素的灰度(即没有rgb通道)。
我们可以使用matplotlib来绘制其中的一些
1 | import matplotlib.pyplot as plt |

2 构建网络
现在让我们开始建立我们的网络。我们将使用两个2d卷积层,然后是两个全连接(或线性)层。作为激活函数,我们将选择整流线性单元(简称ReLUs),作为正则化的手段,我们将使用两个dropout层。在PyTorch中,构建网络的一个好方法是为我们希望构建的网络创建一个新类。让我们在这里导入一些子模块,以获得更具可读性的代码。
1 | import torch.nn as nn |
具体各部分的含义,在下面详细讲!
广义地说,我们可以想到torch.nn层中包含可训练的参数,而torch.nn.functional就是纯粹的功能性。forward()传递定义了使用给定的层和函数计算输出的方式。为了便于调试,在前向传递中打印出张量是完全可以的。在试验更复杂的模型时,这就派上用场了。请注意,前向传递可以使用成员变量甚至数据本身来确定执行路径——它还可以使用多个参数!
现在让我们初始化网络和优化器。
1 | network = Net() |
注意:如果我们使用GPU进行训练,我们也应该使用例如network.cuda()将网络参数发送给GPU。在将网络参数传递给优化器之前,将它们传输到适当的设备是很重要的,否则优化器将无法以正确的方式跟踪它们。
3 模型训练
是时候建立我们的训练循环了。首先,我们要确保我们的网络处于训练模式。然后,每个epoch对所有训练数据进行一次迭代。加载单独批次由DataLoader处理。
首先,我们需要使用optimizer.zero_grad()手动将梯度设置为零,因为PyTorch在默认情况下会累积梯度。然后,我们生成网络的输出(前向传递),并计算输出与真值标签之间的负对数概率损失。现在,我们收集一组新的梯度,并使用optimizer.step()将其传播回每个网络参数。有关PyTorch自动渐变系统内部工作方式的详细信息,请参阅autograd的官方文档(强烈推荐)。
我们还将使用一些打印输出来跟踪进度。为了在以后创建一个良好的培训曲线,我们还创建了两个列表来节省培训和测试损失。在x轴上,我们希望显示网络在培训期间看到的培训示例的数量。
1 | train_losses = [] |
在开始训练之前,我们将运行一次测试循环,看看仅使用随机初始化的网络参数可以获得多大的精度/损失。你能猜出我们的准确度是多少吗?
1 | def train(epoch): |
神经网络模块以及优化器能够使用.state_dict()保存和加载它们的内部状态。这样,如果需要,我们就可以继续从以前保存的状态dict中进行训练——只需调用.load_state_dict(state_dict)。
现在进入测试循环。在这里,我们总结了测试损失,并跟踪正确分类的数字来计算网络的精度。
1 | def test(): |
使用上下文管理器no_grad(),我们可以避免将生成网络输出的计算结果存储在计算图中。
是时候开始训练了!我们将在循环遍历n_epochs之前手动添加test()调用,以使用随机初始化的参数来评估我们的模型。
1 | test() # 不加这个,后面画图就会报错:x and y must be the same size |
4 评估模型的性能
就是这样。仅仅经过3个阶段的训练,我们已经能够达到测试集97%的准确率!我们开始使用随机初始化的参数,正如预期的那样,在开始训练之前,测试集的准确率只有10%左右。
我们来画一下训练曲线。
1 | test() |
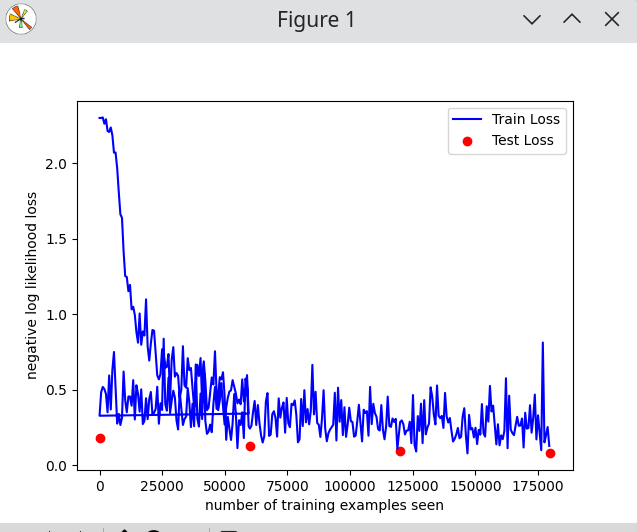
从训练曲线来看,看起来我们甚至可以继续训练几个epoch!
但在此之前,让我们再看看几个例子,正如我们之前所做的,并比较模型的输出。
1 | examples = enumerate(test_loader) |

我们的模型对这些例子的预测似乎是正确的!
5 检查点的持续训练
现在让我们继续对网络进行训练,或者看看如何从第一次培训运行时保存的state_dicts中继续进行训练。我们将初始化一组新的网络和优化器。
1 | continued_network = Net() |
使用.load_state_dict(),我们现在可以加载网络的内部状态,并在最后一次保存它们时优化它们。
1 | network_state_dict = torch.load('model.pth') |
同样,运行一个训练循环应该立即恢复我们之前的训练。为了检查这一点,我们只需使用与前面相同的列表来跟踪损失值。由于我们为所看到的训练示例的数量构建测试计数器的方式,我们必须在这里手动添加它。
1 | # 注意不要注释前面的“for epoch in range(1, n_epochs + 1):”部分, |
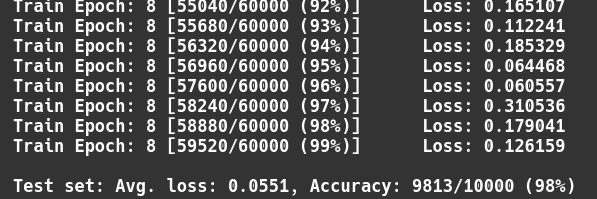
太棒了!我们再次看到测试集的准确性从一个epoch到另一个epoch有了(运行更慢的,慢的多了)提高。让我们用图像来进一步检查训练进度。
1 | fig = plt.figure() |
(我没跑出了,但)
这看起来仍然像一个相当平滑的学习曲线,就像我们最初要训练8个epoch!请记住,我们只是将值添加到从第5个红点开始的相同列表中。
由此我们可以得出两个结论:
从检查点内部状态继续按预期工作。
我们似乎仍然没有遇到过拟合问题!看起来我们的dropout层做了一个很好的规范模型。
6 总结
总之,我们使用PyTorch和TorchVision构建了一个新环境,并使用它从MNIST数据集中对手写数字进行分类,希望使用PyTorch开发出一个良好的直觉。对于进一步的信息,官方的PyTorch文档确实写得很好,论坛也很活跃!
7 完整代码
1 | import torch |